Wie kann die Diagnose verbessert werden, damit möglichst viele Betroffene frühzeitig erkannt werden?
Worum geht es in diesem Forschungsprojekt?
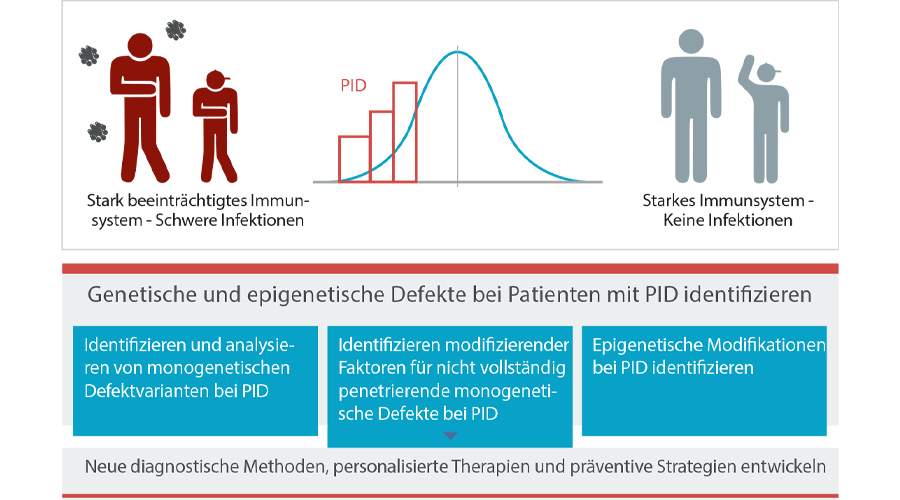
Die Fitness des Immunsystems und damit die Anfälligkeit für Infektionen zeigt eine Gauß’sche Verteilung in der Bevölkerung. Die Variabilität der Anfälligkeit für Infektionskrankheiten basiert auf der genetischen Variation.
Worum geht es in diesem Forschungsprojekt?
Die Fitness des Immunsystems ist in der Bevölkerung ungleich verteilt. Einerseits gibt es Einzelberichte über den „90-jährigen Raucher, der noch nie ins Krankenhaus eingeliefert wurde“, andererseits gibt es immungeschwächte Personen, die ohne medizinische Intervention nicht überleben würden und manchmal sogar eine Knochenmarktransplantation brauchen. Diese Personen mit einem stark beeinträchtigten Immunsystem haben schwere und oft untypische (z. B. opportunistische) lebensbedrohliche Infektionen und eine Veranlagung zu (hauptsächlich viral induzierten) malignen Erkrankungen. Zwischen diesen beiden Extremen gibt es jedoch eine Verteilung der Immuntauglichkeit, bei der Patientinnen und Patienten mit wiederkehrenden, nicht lebensbedrohlichen – aber wiederholten oder verlängerten – Infektionen die Mehrzahl der Fälle darstellen. In den letzten Jahrzehnten wurde festgestellt, dass mehr als 350 verschiedene Gene bei Immundefektpatienten mutiert sind.
Wie ist der Stand der Dinge?
Abhängig von der Kohorte der Studie können die mehr als 350 Gene, die mit primären Immundefekten (PID) assoziiert sind, nur etwa 15-60% der Fälle erklären. Sicher, es sind wahrscheinlich noch weitere Gene zu entdecken, aber es ist auch wahrscheinlich, dass unsere Suche nicht tief genug ist und das monogene Modell nicht ausreichend ist, um die diagnostische Odyssee zu erfüllen. Heutzutage werden in der Klinik routinemäßig Next-Generation-Sequencing-Technologien (NGS) eingesetzt, um eine genetische Diagnose zu erhalten. Die meisten PID-Patientinnen und -Patienten werden einer gezielten Gen-Panel-Sequenzierung (targeted gene panel, TGP) oder einer Gesamt-Exom-Sequenzierung (whole exome sequencing, WES) unterzogen, trotzdem bleibt eine erhebliche Anzahl von ihnen nicht diagnostiziert, wie dies für die meisten monogenetischen Erkrankungen der Fall ist. Dafür kann es viele Gründe geben. Erstens sind standard NGS-Bioinformatik-Pipelines nicht speziell dafür ausgelegt, Änderungen der Kopienanzahl (copy number alterations, CNAs) oder Strukturvarianten (SVs) zu erkennen, und diese können übersehen werden. Zweitens beschränkt die Verwendung von TGP oder WES die Suche auf den codierenden Teil des Genoms (2%). Drittens wurden andere ursächliche oder beitragende Faktoren, die mit dem monogenen Modell ausgeschlossen sind, wie das epigenetische Profil, die Regulation der Genexpression oder das Darmmikrobiom, nicht ausreichend untersucht.

Es könnten mehr Patientinnen und Patienten mit Immundefekten registriert werden.
Was sind die Projektziele?
Die Hauptziele sind:
- Die Anzahl der ungelösten Fälle zu reduzieren, da die Mehrheit der Patientinnen und Patienten mit Immunschwäche derzeit nicht diagnostiziert wird
- Unser Verständnis der Funktionsweise des Epigenoms und seiner Rolle bei den primären Immunschwächekrankheiten zu verbessern
- Die Beziehung zwischen dem Darmmikrobiom und der Schwere und Komorbidität der Erkrankung bei PID-Patientinnen und -Patienten mit Malignität, Autoimmunität oder Entzündung zu verstehen
Wie kommen wir da hin?
Der Prozentsatz der positiv diagnostizierten Patientinnen und Patienten könnte erhöht werden. Möglich ist dies durch eine erneute Analyse der WES-Daten mit benutzerdefinierten Bioinformatik-Pipelines oder durch die Verwendung neuartiger alternativer Methoden wie Next Generation Mapping (NGM), um CNAs oder SVs zu erkennen – einschließlich Insertionen, Translokationen und Inversionen – die mit allgemein üblichen Techniken nicht nachweisbar sind. Ein weitere Möglichkeit besteht darin, die epigenetischen DNA-Methylierung-Muster und die Histonmodifikation in einem genomweiten Ansatz zu erforschen. Darüber hinaus können wir durch Sequenzierung des Darmmikrobioms die phylogene und funktionelle Vielfalt der Darmmikrobiota und ihre Rolle bei der Gestaltung des Immunsystems untersuchen. Schließlich könnten Mikrobiomdiversität und Komorbidität bei Patienten mit PID mit der Analyse von intestinalen Immunglobulinen angegangen werden.
Das Projekt A2 bezieht und registriert seine Patientinnen und Patienten aus dem schon seit 2009 bestehenden nationalen Register für immundefekte Patientinnen und Patienten, dem PIDnet Register. Das PIDnet Register ist wiederum Teil des europäischen Immundefektregisters der ESID (European Society for Immunodeficiencies). Da im PIDnet Register die klinischen Daten der Patientinnen und Patienten geführt werden, ist das PIDnet Register ein integraler Bestandteil von RESIST. Zudem bezieht das Projekt Daten und Biomaterialien aus der Kohorte der Klinischen Forschungsgruppe 250 (KFO 250) in die Forschungen ein.

Hochmolekulare DNA-Analyse zur Erkennung von Strukturvarianten des Genoms.
Leitung des Projekts A2
Projekttitel: Infektionsprädisposition bei primären Immundefekten





Publikationen des Projektes A2
Publikationen 2025
LRBA deficiency impairs autophagy and contributes to enhanced antigen presentation and T-cell dysregulation E. Sindram, M. C. Deau, L. A. Ligeon, P. Sanchez-Martin, S. Nestel, S. Jung, et al.EMBO Rep 2025 Accession Number: 40550954 DOI: 10.1038/s44319-025-00504-7
SKIN MANIFESTATIONS IN ADULTS WITH CHRONIC GRANULOMATOUS DISEASE IN THE UNITED KINGDOM L. Campos, C. A. Henríquez, G. Meligonis, S. Tadros, D. M. Lowe, B. Grimbacher, et al. J Allergy Clin Immunol Pract 2025 Accession Number: 40383433 DOI: 10.1016/j.jaip.2025.04.058
Clinical manifestations, disease penetrance, and treatment in individuals with SOCS1 insufficiency: a registry-based and population-based study J. Hadjadj, A. Wolfers, O. Borisov, D. Hazard, R. Leahy, M. Jeanpierre, et al. Lancet Rheumatol 2025 Vol. 7 Issue 6 Pages e391-e402 Accession Number: 40024253 DOI: 10.1016/s2665-9913(24)00348-5
Reappraisal of IgG subclass deficiencies: a retrospective comparative cohort study D. Dogru, Y. Dogru, F. Atschekzei, A. Elsayed, N. Dubrowinskaja, D. Ernst, et al. Front Immunol 2025 Vol. 16 Pages 1552513 Accession Number: 40313941 PMCID: PMC12043879 DOI: 10.3389/fimmu.2025.1552513
A novel hemizygous nonsense variant in DOCK11 causes systemic inflammation and immunodeficiency A. Elsayed, S. von Hardenberg, F. Atschekzei, P. Siek, T. Witte, G. Sogkas, et al. Clin Immunol 2025 Vol. 276 Pages 110504 Accession Number: 40274249 DOI: 10.1016/j.clim.2025.110504
A precision medicine approach to primary immunodeficiency disease: Ataluren strikes nonsense mutations once again L. Lentini, R. Perriera, F. Corrao, R. Melfi, M. Tutone, P. S. Carollo, et al. Mol Ther 2025 Accession Number: 40158206 DOI: 10.1016/j.ymthe.2025.03.045
The intestinal microbiome and metabolome discern disease severity in cytotoxic T-lymphocyte-associated protein 4 deficiency P. Chandrasekaran, M. Krausz, Y. Han, N. Mitsuiki, A. Gabrysch, C. Nöltner, et al. Microbiome 2025 Vol. 13 Issue 1 Pages 51 Accession Number: 39934899 PMCID: PMC11817180 DOI: 10.1186/s40168-025-02028-7
Bruton’s tyrosine kinase (BTK) and matrix metalloproteinase-9 (MMP-9) regulate NLRP3 inflammasome-dependent cytokine and neutrophil extracellular trap responses in primary neutrophils V. N. C. Leal, F. Bork, M. Mateo Tortola, J. C. von Guilleaume, C. L. Greve, S. Bugl, et al. J Allergy Clin Immunol 2025 Vol. 155 Issue 2 Pages 569-582 Accession Number: 39547282 DOI: 10.1016/j.jaci.2024.10.035
The effect of HLA genotype on disease onset and severity in CTLA-4 insufficiency
S. Posadas-Cantera, N. Mitsuiki, F. Emmerich, V. Patiño, H. M. Lorenz, O. Neth, et al. Front Immunol 2025 Vol. 15 Pages 1447995 Accession Number: 39835139 PMCID: PMC11744039 DOI: 10.3389/fimmu.2024.1447995
Distinct Microbial Taxa Are Associated with LDL-Cholesterol Reduction after 12 Weeks of Lactobacillus plantarum Intake in Mild Hypercholesterolemia: Results of a Randomized Controlled Study F. Kerlikowsky, M. Müller, T. Greupner, L. Amend, T. Strowig and A. Hahn Probiotics and Antimicrobial Proteins 2025 DOI: 10.1007/s12602-023-10191-2
Re-evaluation of the contribution of TNFRSF13B variants to antibody deficiency H. Abolhassani, A. Caballero-Oteyza, M. Yang, M. Proietti, S. Delavari, P. Maffucci, et al. J Hum Immun 2025 Vol. 1 Issue 4 Accession Number: 40959164 PMCID: PMC12435966 DOI: 10.70962/jhi.20250016
STAT3 haploinsufficiency is associated with autosomal dominant hyper-IgE syndrome V. Andreani, A. J. Forde, M. Fliegauf, G. Bressan, V. Noé, N. Ott, et al. Sci Adv 2025 Vol. 11 Issue 35 Pages eadw2464 Accession Number: 40880472 PMCID: PMC12396324 DOI: 10.1126/sciadv.adw2464
A germline IκBα mutation outside the signal reception domain blocks nuclear translocation of NFκB1 and associates with autoinflammation-like features A. Elsayed, I. R. Adriawan, F. Atschekzei, N. Dubrowinskaja, M. Anim, F. Hauck, et al. Ann Rheum Dis 2025 Accession Number: 40914709 DOI: 10.1016/j.ard.2025.08.010
Activation of NF-κB Signaling by Optogenetic Clustering of IKKα and β A. A. M. Fischer, M. M. Kramer, M. Baños, M. M. Grimm, M. Fliegauf, B. Grimbacher, et al. Adv Biol (Weinh) 2025 Pages e00384 Accession Number: 40729545 DOI: 10.1002/adbi.202400384
A precision medicine approach to primary immunodeficiency disease: Ataluren strikes nonsense mutations once again L. Lentini, R. Perriera, F. Corrao, R. Melfi, M. Tutone, P. S. Carollo, et al. Mol Ther 2025 Vol. 33 Issue 7 Pages 3231-3241 Accession Number: 40158206 PMCID: PMC12266018 DOI: 10.1016/j.ymthe.2025.03.045
Inborn errors of immunity: Manifestation, treatment, and outcome-an ESID registry 1994-2024 report on 30,628 patients G. Kindle, M. Alligon, M. H. Albert, M. Buckland, J. D. Edgar, B. Gathmann, et al. J Hum Immun 2025 Vol. 1 Issue 3 Accession Number: 41347188 PMCID: PMC12674179 DOI: 10.70962/jhi.20250007
Publikationen 2024
Novel hypermorphic variants in IRF2BP2 identified in patients with common variable immunodeficiency and autoimmunity M. Anim, G. Sogkas, N. Camacho-Ordonez, G. Schmidt, A. Elsayed, M. Proietti, et al. Clin Immunol 2024 Vol. 266 Pages 110326 Accession Number: 39059757 DOI: 10.1016/j.clim.2024.110326
Abnormal biomarkers predict complex FAS or FADD defects missed by exome sequencing. Rensing-Ehl A, Lorenz MR, Führer M, Willenbacher W, Willenbacher E, Sopper S, Abinun M, Maccari ME, König C, Haegele P, Fuchs S, Castro C, Kury P, Pelle O, Klemann C, Heeg M, Thalhammer J, Wegehaupt O, Fischer M, Goldacker S, Schulte B, Biskup S, Chatelain P, Schuster V, Warnatz K, Grimbacher B, Meinhardt A, Holzinger D, Oommen PT, Hinze T, Hebart H, Seeger K, Lehmberg K, Leahy TR, Claviez A, Vieth S, Schilling FH, Fuchs I, Groß M, Rieux-Laucat F, Magerus A, Speckmann C, Schwarz K, Ehl S; ALPS Study Group. J Allergy Clin Immunol. 2024 Jan;153(1):297-308.e12. doi: 10.1016/j.jaci.2023.11.006. Epub 2023 Nov 17. PMID: 37979702.
Epigenetic immune cell quantification for diagnostic evaluation and monitoring of patients with inborn errors of immunity and secondary immune deficiencies. Ramirez NJ, Schulze JJ, Walter S, Werner J, Mrovecova P, Olek S, Sachsenmaier C, Grimbacher B, Salzer U. Clin Immunol. 2024 Mar;260:109920. doi: 10.1016/j.clim.2024.109920. Epub 2024 Feb 1. PMID: 38307474.
Engineering Material Properties of Transcription Factor Condensates to Control Gene Expression in Mammalian Cells and Mice. Fischer, A. A. M., H. B. Robertson, D. Kong, M. M. Grimm, J. Grether, J. Groth, C. Baltes, M. Fliegauf, F. Lautenschläger, B. Grimbacher, H. Ye, V. Helms, and W. Weber. 2024. Small: e2311834.
Phenotypic and pathomechanistic overlap between tapasin and TAP deficiencies. Elsayed, A., S. von Hardenberg, F. Atschekzei, T. Graalmann, C. Jänke, T. Witte, F. C. Ringshausen, and G. Sogkas. 2024. J Allergy Clin Immunol.
Current genetic diagnostics in inborn errors of immunity. Sake, S. M., X. Zhang, M. K. Rajak, M. Urbanek-Quaing, A. Carpentier, A. P. Gunesch, C. Grethe, A. Matthaei, J. Ruckert, M. Galloux, T. Larcher, R. Le Goffic, F. Hontonnou, A. K. Chatterjee, K., Hardenberg, S., I. Klefenz, D. Steinemann, N. Di Donato, U. Baumann, B. Auber, and C. Klemann. 2024. Front Pediatr 12: 1279112.
B-cells absence in patients diagnosed as inborn errors of immunity: a registry-based study. Khoshnevisan, R., S. Hassanzadeh, C. Klein, M. Rohlfs, B. Grimbacher, N. Molavi, A. Zamanifar, A. Khoshnevisan, M. Jafari, B. Bagherpour, M. Behnam, S. Najafi, and R. Sherkat. 2024. Immunogenetics 76: 189-202.
PLCG2-associated immune dysregulation (PLAID) comprises broad and distinct clinical presentations related to functional classes of genetic variants. Baysac K, Sun G, Nakano H, Schmitz EG, Cruz AC, Fisher C, Bailey AC; PLCG2-Immune Dysregulation Working Group; Mace E, Milner JD, Ombrello MJ. J Allergy Clin Immunol. 2024 Jan;153(1):230-242. doi: 10.1016/j.jaci.2023.08.036. Epub 2023 Sep 26. PMID: 37769878
Type-Specific Impacts of Protein Defects in Pathogenic NFKB2 Variants: Novel Clinical Findings From 138 Patients
J. Meissner, M. Fliegauf, B. Grimbacher and C. Klemann J Allergy Clin Immunol Pract 2024 Accession Number: 39447838 DOI: 10.1016/j.jaip.2024.10.015
PGM3 insufficiency: a glycosylation disorder causing a notable T cell defect L. Yang, B. Zerbato, A. Pessina, L. Brambilla, V. Andreani, S. Frey-Jakobs, et al. Front Immunol 2024 Vol. 15 Pages 1500381 Accession Number: 39776909 PMCID: PMC11703855 DOI: 10.3389/fimmu.2024.1500381
Inborn Errors of Immunity (IEI) breaking immune homeostasis and tolerance: a key role for T regulatory cells
V. De Rosa, G. Sogkas and R. Bacchetta Front Immunol 2024 Vol. 15 Pages 1532079
Accession Number: 39749344 PMCID: PMC11693703 DOI: 10.3389/fimmu.2024.1532079
Deciphering the molecular complexity of the IKZF1plus genomic profile using Optical Genome Mapping
Jonathan L Lühmann , Martin Zimmermann , Winfried Hofmann , Anke K Bergmann , Anja Möricke , Gunnar Cario , Martin Schrappe , Brigitte Schlegelberger , Martin Stanulla , Doris Steinemann
Haematologica. 2024 May 1;109(5):1582-1587. doi: 10.3324/haematol.2023.284115.
Publikationen 2023
An expanded CRISPR-Cas9-assisted recombineering toolkit for engineering genetically intractable Pseudomonas aeruginosa isolates D. Pankratz, N. O. Gomez, A. Nielsen, A. Mustafayeva, M. Gür, F. Arce-Rodriguez, et al. Nature Protocols 2023 Vol. 18 Issue 11 Pages 3253-3288 DOI: 10.1038/s41596-023-00882-z
Rituximab to treat prolidase deficiency due to a novel pathogenic copy number variation in PEPD
Faranaz Atschekzei , Mykola Fedchenko , Abdulwahab Elsayed , Natalia Dubrowinskaja , Theresa Graalmann , Felix C Ringshausen , Torsten Witte , Georgios Sogkas
RMD Open. 2023 Dec 7;9(4):e003507. doi: 10.1136/rmdopen-2023-003507.
MAGT1 Deficiency Dysregulates Platelet Cation Homeostasis and Accelerates Arterial Thrombosis and Ischemic Stroke in Mice. Gotru SK, Mammadova-Bach E, Sogkas G, Schuhmann MK, Schmitt K, Kraft P, Herterich S, Mamtimin M, Pinarci A, Beck S, Stritt S, Han C, Ren P, Freund JN, Klemann C, Ringshausen FC, Heemskerk JWM, Dietrich A, Nieswandt B, Stoll G, Gudermann T, Braun A. Arterioscler Thromb Vasc Biol. 2023 Aug;43(8):1494-1509. doi: 10.1161/ATVBAHA.122.318115. Epub 2023 Jun 29. PMID: 37381987.
Future Directions in the Diagnosis and Treatment of APDS and IEI: a Survey of German IEI Centers. Vanselow S, Hanitsch L, Hauck F, Körholz J, Maccari ME, Meinhardt A, Sogkas G, Schuetz C, Grimbacher B. Front Immunol. 2023 Oct 5;14:1279652.
A Toolkit for Monitoring Immunoglobulin G Levels from Dried Blood Spots of Patients with Primary Immunodeficiencies. Haberstroh H, Hirsch A, Goldacker S, Zessack N, Warnatz K, Grimbacher B, Salzer U. J Clin Immunol. 2023 Aug;43(6):1185-1192. doi: 10.1007/s10875-023-01464-0. Epub 2023 Mar 21.
JAKs and STATs from a Clinical Perspective: Loss-of-Function Mutations, Gain-of-Function Mutations, and Their Multidimensional Consequences Ott N, Faletti L, Heeg M, Andreani V, Grimbacher B. . J Clin Immunol. 2023 Aug;43(6):1326-1359.
Sequencing the B Cell Receptor Repertoires of Antibody-Deficient Individuals With and Without Infection Susceptibility. Lim YW, Ramirez NJ, Asensio MA, Chiang Y, Müller G, Mrovecova P, Mitsuiki N, Krausz M, Camacho-Ordonez N, Warnatz K, Adler AS, Grimbacher B. J Clin Immunol. 2023 Feb 24.
The link between rheumatic disorders and inborn errors of immunity. Sogkas G, Witte T. EBioMedicine. 2023 Mar 2;90:104501.
The GAIN Registry – a New Prospective Study for Patients with Multi-organ Autoimmunity and Autoinflammation. Staus P, Rusch S, El-Helou S, Müller G, Krausz M, Geisen U, Caballero-Oteyza A, Krüger R, Bakhtiar S, Lee-Kirsch MA, Fasshauer M, Baumann U, Hoyer BF, Farela Neves J, Borte M, Carrabba M, Hauck F, Ehl S, Bader P, von Bernuth H, Atschekzei F, Seppänen MRJ, Warnatz K, Nieters A, Kindle G, Grimbacher B. J Clin Immunol. 2023 Apr 21:1–13.
Activated Phosphoinositide 3-Kinase δ Syndrome: Update from the ESID Registry and comparison with other autoimmune-lymphoproliferative inborn errors of immunity. Maccari ME, Wolkewitz M, Schwab C, Lorenzini T, Leiding JW, Aladjdi N, Abolhassani H, Abou-Chahla W, Aiuti A, Azarnoush S, Baris S, Barlogis V, Barzaghi F, Baumann U, Bloomfield M, Bohynikova N, Bodet D, Boutboul D, Bucciol G, Buckland MS, Burns SO, Cancrini C, Cathébras P, Cavazzana M, Cheminant M, Chinello M, Ciznar P, Coulter TI, D’Aveni M, Ekwall O, Eric Z, Eren E, Fasth A, Frange P, Fournier B, Garcia-Prat M, Gardembas M, Geier C, Ghosh S, Goda V, Hammarstrom L, Hauck F, Heeg M, Heropolitanska-Pliszka E, Hilfanova A, Jolles S, Karakoc-Aydiner E, Kindle GR, Klemann C, Koletsi P, Koltan S, Kondratenko I, Körholz J, Krüger R, Jeziorski E, Levy R, Le Guenno G, Lefevre G, Lougaris V, Marzollo A, Mahlaoui N, Malphettes M, Meinhardt A, Merlin E, Meyts I, Milota T, Moreira F, Moshous D, Mukhina A, Neth O, Neubert J, Neven B, Nieters A, Nove-Josserand R, Oksenhendler E, Ozen A, Olbrich P, Perlat A, Pac M, Schmid JP, Pacillo L, Parra-Martinez A, Paschenko O, Pellier I, Sefer AP, Plebani A, Plantaz D, Prader S, Raffray L, Ritterbusch H, Riviere JG, Rivalta B, Rusch S, Sakovich I, Savic S, Scheible R, Schleinitz N, Schuetz C, Schulz A, Sediva A, Semeraro M, Sharapova SO, Shcherbina A, Slatter MA, Sogkas G, Soler-Palacin P, Speckmann C, Stephan JL, Suarez F, Tommasini A, Trück J, Uhlmann A, van Aerde KJ, van Montfrans J, von Bernuth H, Warnatz K, Williams T, Worth AJ, Ip W, Picard C, Catherinot E, Nademi Z, Grimbacher B, Forbes Satter LR, Kracker S, Chandra A, Condliffe AM, Ehl S; European Society for Immunodeficiencies Registry Working Party. J Allergy Clin Immunol. 2023 Jun 28:S0091-6749(23)00812-6.
Common Variable Immunodeficiency: More Pathways than Roads to Rome. Peng XP, Caballero-Oteyza A, Grimbacher B. Annu Rev Pathol. 2023 Jan 24;18:283-310. doi: 10.1146/annurev-pathmechdis-031521-024229. Epub 2022 Oct 20. PMID: 36266261.
Functional Relevance of CTLA4 Variants: an Upgraded Approach to Assess CTLA4-Dependent Transendocytosis by Flow Cytometry. Rojas-Restrepo J, Sindram E, Zenke S, Haberstroh H, Mitsuiki N, Gabrysch A, Huebscher K, Posadas-Cantera S, Krausz M, Kobbe R, Rohr JC, Grimbacher B, Gámez-Díaz L. J Clin Immunol. 2023 Nov;43(8):2076-2089. doi: 10.1007/s10875-023-01582-9. Epub 2023 Sep 23. Erratum in: J Clin Immunol. 2023 Oct 9;: PMID: 37740092; PMCID: PMC10661720.
Next generation sequencing (NGS)-based approach to diagnosing Algerian patients with suspected inborn errors of immunity (IEIs). Peng XP, Al-Ddafari MS, Caballero-Oteyza A, El Mezouar C, Mrovecova P, Dib SE, Massen Z, Smahi MC, Faiza A, Hassaïne RT, Lefranc G, Aribi M, Grimbacher B. Clin Immunol. 2023 Nov;256:109758. doi: 10.1016/j.clim.2023.109758. Epub 2023 Sep 9. PMID: 37678716.
Telomere biology disorders may manifest as common variable immunodeficiency (CVID). Rolles B, Caballero-Oteyza A, Proietti M, Goldacker S, Warnatz K, Camacho-Ordonez N, Prader S, Schmid JP, Vieri M, Isfort S, Meyer R, Kirschner M, Brümmendorf TH, Beier F, Grimbacher B. Clin Immunol. 2023 Dec;257:109837. doi: 10.1016/j.clim.2023.109837. Epub 2023 Nov 8. PMID: 37944684.
Efficacy of dupilumab for the treatment of severe skin disease in cytotoxic T lymphocyte antigen-4 insufficiency: A role of type 2 inflammation? Arruda LK, Cordeiro DL, Langer SS, Koenigham-Santos M, Calado RT, Dias MM, Anhesini LR, Oliveira JB, Grimbacher B, Ferriani MPL. J Allergy Clin Immunol Glob. 2023 Sep 22;2(1):114-117. doi: 10.1016/j.jacig.2022.08.004. PMID: 37780100; PMCID: PMC10509893.
Publikationen 2022
Pembrolizumab for treatment of progressive multifocal leukoencephalopathy in primary immunodeficiency and/or hematologic malignancy: a case series of five patients. Volk T, Warnatz K, Marks R, Urbach H, Schluh G, Strohmeier V, Rojas-Restrepo J, Grimbacher B, Rauer S. J Neurol. 2022 Jul 1. doi: 10.1007/s00415-021-10682-8. Online ahead of print. PMID: 34196768
Identification of variants in genes associated with autoinflammatory disorders in a cohort of patients with psoriatic arthritis F. Atschekzei, N. Dubrowinskaja, M. Anim, T. Thiele, T. Witte and G. Sogkas RMD Open 2022 Vol. 8 Issue 2 Accession Number: 36113963 PMCID: PMC9486391 DOI: 10.1136/rmdopen-2022-002561
Resolving the polygenic aetiology of a late onset combined immune deficiency caused by NFKB1 haploinsufficiency and modified by PIK3R1 and TNFRSF13B variants. Hargreaves CE, Dhalla F, Patel AM, de Oteyza ACG, Bateman E, Miller J, Anzilotti C, Ayers L, Grimbacher B, Patel SY. Clin Immunol. 2022 Jan;234:108910. doi: 10.1016/j.clim.2021.108910. Epub 2021 Dec 15. PMID: 34922003.
Phenotype, genotype, treatment, and survival outcomes in patients with X-linked inhibitor of apoptosis deficiency. Yang L, Booth C, Speckmann C, Seidel MG, Worth AJJ, Kindle G, Lankester AC, Grimbacher B; ESID Clinical and Registry Working Parties; Gennery AR, Seppanen MRJ, Morris EC, Burns SO. J Allergy Clin Immunol. 2022 Aug;150(2):456-466. doi: 10.1016/j.jaci.2021.10.037. Epub 2021 Dec 15. PMID: 34920033.
Confirmation of Hyperimmunoglobulin E Syndrome in Two Patients with an Ocular Problem: Detection of Two New DOCK8 Mutations. Saghafi S, Zandieh F, Fazlollahi MR, Glocker C, Frede N, Buchta M, Yang L, Mahmoudi AH, Houshmand M, Pourpak Z, Grimbacher B, Moin M. Iran J Allergy Asthma Immunol. 2022 Jun 18;21(3):355-363. doi: 10.18502/ijaai.v21i3.9809. PMID: 35822685.
Do common infections trigger disease-onset or -severity in CTLA-4 insufficiency? Krausz M, Mitsuiki N, Falcone V, Komp J, Posadas-Cantera S, Lorenz HM, Litzman J, Wolff D, Kanariou M, Heinkele A, Speckmann C, Häcker G, Hengel H, Gámez-Díaz L, Grimbacher B. Front Immunol. 2022 Nov 2;13:1011646.
Allele-Specific Disruption of a Common STAT3 Autosomal Dominant Allele Is Not Sufficient to Restore Downstream Signaling in Patient-Derived T Cells. König S, Fliegauf M, Rhiel M, Grimbacher B, Cornu TI, Cathomen T, Mussolino C. Genes (Basel). 2022 Oct 20;13(10):1912.
Diagnostic Yield and Therapeutic Consequences of Targeted Next-Generation Sequencing in Sporadic Primary Immunodeficiency. Sogkas G, Dubrowinskaja N, Schütz K, Steinbrück L, Götting J, Schwerk N, Baumann U, Grimbacher B, Witte T, Schmidt RE, Atschekzei F. Int Arch Allergy Immunol. 2022;183(3):337-349.
Dysregulated PI3K Signaling in B Cells of CVID Patients. Harder I, Münchhalfen M, Andrieux G, Boerries M, Grimbacher B, Eibel H, Maccari ME, Ehl S, Wienands J, Jellusova J, Warnatz K, Keller B. Cells. 2022 Jan 28;11(3):464. doi: 10.3390/cells11030464.
Phenotypic spectrum in recessive STING-associated vasculopathy with onset in infancy: Four novel cases and analysis of previously reported cases. Wan R, Fänder J, Zakaraia I, Lee-Kirsch MA, Wolf C, Lucas N, Olfe LI, Hendrich C, Jonigk D, Holzinger D, Steindor M, Schmidt G, Davenport C, Klemann C, Schwerk N, Griese M, Schlegelberger B, Stehling F, Happle C, Auber B, Steinemann D, Wetzke M, von Hardenberg S. Front Immunol. 2022 Oct 6;13:1029423.
Copy Number Analysis in a Large Cohort Suggestive of Inborn Errors of Immunity Indicates a Wide Spectrum of Relevant Chromosomal Losses and Gains. Wan R, Schieck M, Caballero-Oteyza A, Hofmann W, Cochino AV, Shcherbina A, Sherkat R, Wache-Mainier C, Fernandez A, Sultan M, Illig T, Grimbacher B, Proietti M, Steinemann D. J Clin Immunol. 2022 Jul;42(5):1083-1092.
Bowel Histology of CVID Patients Reveals Distinct Patterns of Mucosal Inflammation.van Schewick CM, Lowe DM, Burns SO, Workman S, Symes A, Guzman D, Moreira F, Watkins J, Clark I, Grimbacher B. J Clin Immunol. 2022 Oct 1. doi: 10.1007/s10875-021-01104-5. Epub ahead of print. PMID: 34599484.
Therapeutic options for CTLA-4 insufficiency. Egg D, Rump IC, Mitsuiki N, Rojas-Restrepo J, Maccari ME, Schwab C, Gabrysch A, Warnatz K, Goldacker S, Patiño V, Wolff D, Okada S, Hayakawa S, Shikama Y, Kanda K, Imai K, Sotomatsu M, Kuwashima M, Kamiya T, Morio T, Matsumoto K, Mori T, Yoshimoto Y, Dybedal I, Kanariou M, Kucuk ZY, Chapdelaine H, Petruzelkova L, Lorenz HM, Sullivan KE, Heimall J, Moutschen M, Litzman J, Recher M, Albert MH, Hauck F, Seneviratne S, Pachlopnik Schmid J, Kolios A, Unglik G, Klemann C, Snapper S, Giulino-Roth L, Svaton M, Platt CD, Hambleton S, Neth O, Gosse G, Reinsch S, Holzinger D, Kim YJ, Bakhtiar S, Atschekzei F, Schmidt R, Sogkas G, Chandrakasan S, Rae W, Derfalvi B, Marquart HV, Ozen A, Kiykim A, Karakoc-Aydiner E, Králíčková P, de Bree G, Kiritsi D, Seidel MG, Kobbe R, Dantzer J, Alsina L, Armangue T, Lougaris V, Agyeman P, Nyström S, Buchbinder D, Arkwright PD, Grimbacher B. J Allergy Clin Immunol. 2022 Jun 7:S0091-6749(21)00891-5. doi: 10.1016/j.jaci.2021.04.039. Online ahead of print. PMID: 34111452
Publikationen 2021
High frequency of variants in genes associated with primary immunodeficiencies in patients with rheumatic diseases with secondary hypogammaglobulinaemia. Sogkas G, Dubrowinskaja N, Adriawan IR, Anim M, Witte T, Schmidt RE, Atschekzei F. Ann Rheum Dis. 2021 Mar;80(3):392-399.
A Pathogenic Missense Variant in NFKB1 Causes Common Variable Immunodeficiency Due to Detrimental Protein Damage. Fliegauf M, Krüger R, Steiner S, Hanitsch LG, Büchel S, Wahn V, von Bernuth H, Grimbacher B. Front Immunol. 2021 Apr 27;12:621503.
There is no gene for CVID – novel monogenetic causes for primary antibody deficiency. Ramirez NJ, Posadas-Cantera S, Caballero-Oteyza A, Camacho-Ordonez N, Grimbacher B. Curr Opin Immunol. 2021 Jun 18;72:176-185. doi: 10.1016/j.coi.2021.05.010. Online ahead of print. PMID: 34153571 Review.
TACI deficiency – a complex system out of balance. Salzer U, Grimbacher B. Curr Opin Immunol. 2021 Jul 8;71:81-88. doi: 10.1016/j.coi.2021.06.004. Online ahead of print. PMID: 34247095 Review.
Cellular and molecular mechanisms breaking immune tolerance in inborn errors of immunity. Sogkas G, Atschekzei F, Adriawan IR, Dubrowinskaja N, Witte T, Schmidt RE. Cell Mol Immunol. 2021 Apr 1:1-19. doi: 10.1038/s41423-020-00626-z. Online ahead of print. PMID: 33795850 Free PMC article. Review.
Beyond „Big Eaters“: The Versatile Role of Alveolar Macrophages in Health and Disease. Hetzel M, Ackermann M, Lachmann N. Int J Mol Sci. 2021 Mar 24;22(7):3308. doi: 10.3390/ijms22073308. PMID: 33804918 Free PMC article. Review.
A distinct CD38+CD45RA+ population of CD4+, CD8+, and double-negative T cells is controlled by FAS. Maccari ME, Fuchs S, Kury P, Andrieux G, Völkl S, Bengsch B, Lorenz MR, Heeg M, Rohr J, Jägle S, Castro CN, Groß M, Warthorst U, König C, Fuchs I, Speckmann C, Thalhammer J, Kapp FG, Seidel MG, Dückers G, Schönberger S, Schütz C, Führer M, Kobbe R, Holzinger D, Klemann C, Smisek P, Owens S, Horneff G, Kolb R, Naumann-Bartsch N, Miano M, Staniek J, Rizzi M, Kalina T, Schneider P, Erxleben A, Backofen R, Ekici A, Niemeyer CM, Warnatz K, Grimbacher B, Eibel H, Mackensen A, Frei AP, Schwarz K, Boerries M, Ehl S, Rensing-Ehl A. J Exp Med. 2021 Feb 1;218(2):e20192191. doi: 10.1084/jem.20192191. PMID: 33170215; PMCID: PMC7658692.
Biochemically deleterious human NFKB1 variants underlie an autosomal dominant form of common variable immunodeficiency. Li J, Lei WT, Zhang P, Rapaport F, Seeleuthner Y, Lyu B, Asano T, Rosain J, Hammadi B, Zhang Y, Pelham SJ, Spaan AN, Migaud M, Hum D, Bigio B, Chrabieh M, Béziat V, Bustamante J, Zhang SY, Jouanguy E, Boisson-Dupuis S, El Baghdadi J, Aimanianda V, Thoma K, Fliegauf M, Grimbacher B, Korganow AS, Saunders C, Rao VK, Uzel G, Freeman AF, Holland SM, Su HC, Cunningham-Rundles C, Fieschi C, Abel L, Puel A, Cobat A, Casanova JL, Zhang Q, Boisson B. J Exp Med. 2021 Nov 1;218(11):e20210566. doi: 10.1084/jem.20210566. Epub 2021 Sep 2. PMID: 34473196; PMCID: PMC8421261.
BTK operates a phospho-tyrosine switch to regulate NLRP3 inflammasome activity. Bittner ZA, Liu X, Mateo Tortola M, Tapia-Abellán A, Shankar S, Andreeva L, Mangan M, Spalinger M, Kalbacher H, Düwell P, Lovotti M, Bosch K, Dickhöfer S, Marcu A, Stevanović S, Herster F, Cardona Gloria Y, Chang TH, Bork F, Greve CL, Löffler MW, Wolz OO, Schilling NA, Kümmerle-Deschner JB, Wagner S, Delor A, Grimbacher B, Hantschel O, Scharl M, Wu H, Latz E, Weber ANR. J Exp Med. 2021 Nov 1;218(11):e20201656. doi: 10.1084/jem.20201656. Epub 2021 Sep 23. PMID: 34554188; PMCID: PMC8480672.
Hematopoietic Stem Cell Transplantation Resolves the Immune Deficit Associated with STAT3-Dominant-Negative Hyper-IgE Syndrome. Harrison SC, Tsilifis C, Slatter MA, Nademi Z, Worth A, Veys P, Ponsford MJ, Jolles S, Al-Herz W, Flood T, Cant AJ, Doffinger R, Barcenas-Morales G, Carpenter B, Hough R, Haraldsson Á, Heimall J, Grimbacher B, Abinun M, Gennery AR. J Clin Immunol. 2021 Jul;41(5):934-943. doi: 10.1007/s10875-021-00971-2. Epub 2021 Feb 1. PMID: 33523338; PMCID: PMC8249289.
Immune checkpoint deficiencies and autoimmune lymphoproliferative syndromes. Gámez-Díaz L, Grimbacher B. Biomed J. 2021 Aug;44(4):400-411. doi: 10.1016/j.bj.2021.04.005. Epub 2021 Apr 19. PMID: 34384744; PMCID: PMC8514790.
Initial presenting manifestations in 16,486 patients with inborn errors of immunity include infections and noninfectious manifestations. Thalhammer J, Kindle G, Nieters A, Rusch S, Seppänen MRJ, Fischer A, Grimbacher B, Edgar D, Buckland M, Mahlaoui N, Ehl S; European Society for Immunodeficiencies Registry Working Party. J Allergy Clin Immunol. 2021 Nov;148(5):1332-1341.e5. doi: 10.1016/j.jaci.2021.04.015. Epub 2021 Apr 23. PMID: 33895260.
The expansion of human T-bethighCD21low B cells is T cell dependent. Keller B, Strohmeier V, Harder I, Unger S, Payne KJ, Andrieux G, Boerries M, Felixberger PT, Landry JJM, Nieters A, Rensing-Ehl A, Salzer U, Frede N, Usadel S, Elling R, Speckmann C, Hainmann I, Ralph E, Gilmour K, Wentink MWJ, van der Burg M, Kuehn HS, Rosenzweig SD, Kölsch U, von Bernuth H, Kaiser-Labusch P, Gothe F, Hambleton S, Vlagea AD, Garcia Garcia A, Alsina L, Markelj G, Avcin T, Vasconcelos J, Guedes M, Ding JY, Ku CL, Shadur B, Avery DT, Venhoff N, Thiel J, Becker H, Erazo-Borrás L, Trujillo-Vargas CM, Franco JL, Fieschi C, Okada S, Gray PE, Uzel G, Casanova JL, Fliegauf M, Grimbacher B, Eibel H, Ehl S, Voll RE, Rizzi M, Stepensky P, Benes V, Ma CS, Bossen C, Tangye SG, Warnatz K. Sci Immunol. 2021 Oct 15;6(64):eabh0891. doi: 10.1126/sciimmunol.abh0891. Epub 2021 Oct 8. PMID: 34623902.
Vulnerability to Meningococcal Disease in Immunodeficiency Due to a Novel Pathogenic Missense Variant in NFKB1. Anim M, Sogkas G, Schmidt G, Dubrowinskaja N, Witte T, Schmidt RE, Atschekzei F. Front Immunol. 2021 Dec 24;12:767188. doi: 10.3389/fimmu.2021.767188. Erratum in: Front Immunol. 2023 May 10;14:1212029. PMID: 35003082; PMCID: PMC8738076.
What can clinical immunology learn from inborn errors of epigenetic regulators? Camacho-Ordonez N, Ballestar E, Timmers HTM, Grimbacher B. J Allergy Clin Immunol. 2021 May;147(5):1602-1618. doi: 10.1016/j.jaci.2021.01.035. Epub 2021 Feb 17. PMID: 33609625.
Publikationen 2020
Dynamics in protein translation sustaining T cell preparedness. Wolf T, Jin W, Zoppi G, Vogel IA, Akhmedov M, Bleck CKE, Beltraminelli T, Rieckmann JC, Ramirez NJ, Benevento M, Notarbartolo S, Bumann D, Meissner F, Grimbacher B, Mann M, Lanzavecchia A, Sallusto F, Kwee I, Geiger R. Nat Immunol. 2020 Aug;21(8):927-937.
Altered Microbiota, Impaired Quality of Life, Malabsorption, Infection, and Inflammation in CVID Patients With Diarrhoea. van Schewick CM, Nöltner C, Abel S, Burns SO, Workman S, Symes A, Guzman D, Proietti M, Bulashevska A, Moreira F, Soetedjo V, Lowe DM, Grimbacher B. Front Immunol. 2020 Jul 31;11:1654.
Dominant-negative mutations in human IL6ST underlie hyper-IgE syndrome. Béziat V, Tavernier SJ, Chen YH, Ma CS, Materna M, Laurence A, Staal J, Aschenbrenner D, Roels L, Worley L, Claes K, Gartner L, Kohn LA, De Bruyne M, Schmitz-Abe K, Charbonnier LM, Keles S, Nammour J, Vladikine N, Maglorius Renkilaraj MRL, Seeleuthner Y, Migaud M, Rosain J, Jeljeli M, Boisson B, Van Braeckel E, Rosenfeld JA, Dai H, Burrage LC, Murdock DR, Lambrecht BN, Avettand- Fenoel V, Vogel TP; Undiagnosed Diseases Network, Esther CR, Haskologlu S, Dogu F, Ciznar P, Boutboul D, Ouachée-Chardin M, Amourette J, Lebras MN, Gauvain C, Tcherakian C, Ikinciogullari A, Beyaert R, Abel L, Milner JD, Grimbacher B, Couderc LJ, Butte MJ, Freeman AF, Catherinot É, Fieschi C, Chatila TA, Tangye SG, Uhlig HH, Haerynck F, Casanova JL, Puel A. J Exp Med. 2020 Jun 1;217(6):e20191804.“
Characterization of the clinical and immunologic phenotype and management of 157 individuals with 56 distinct heterozygous NFKB1 mutations. Lorenzini T, Fliegauf M, Klammer N, Frede N, Proietti M, Bulashevska A, Camacho-Ordonez N, Varjosalo M, Kinnunen M, de Vries E, van der Meer JWM, Ameratunga R, Roifman CM, Schejter YD, Kobbe R, Hautala T, Atschekzei F, Schmidt RE, Schröder C, Stepensky P, Shadur B, Pedroza LA, van der Flier M, Martínez-Gallo M, Gonzalez-Granado LI, Allende LM, Shcherbina A, Kuzmenko N, Zakharova V, Neves JF, Svec P, Fischer U, Ip W, Bartsch O, Barış S, Klein C, Geha R, Chou J, Alosaimi M, Weintraub L, Boztug K, Hirschmugl T, Dos Santos Vilela MM, Holzinger D, Seidl M, Lougaris V, Plebani A, Alsina L, Piquer-Gibert M, Deyà-Martínez A, Slade CA, Aghamohammadi A, Abolhassani H, Hammarström L, Kuismin O, Helminen M, Allen HL, Thaventhiran JE, Freeman AF, Cook M, Bakhtiar S, Christiansen M, Cunningham-Rundles C, Patel NC, Rae W, Niehues T, Brauer N, Syrjänen J, Seppänen MRJ, Burns SO, Tuijnenburg P, Kuijpers TW; NIHR-BioResource – Rare Diseases Consortium, Warnatz K, Grimbacher B. J Allergy Clin Immunol. 2020 Apr 9:S0091-6749(20)30422-X.
Nonpermissive bone marrow environment impairs early B-cell development in common variable immunodeficiency. Troilo A, Wehr C, Janowska I, Venhoff N, Thiel J, Rawluk J, Frede N, Staniek J, Lorenzetti R, Schleyer MT, Herget GW, Konstantinidis L, Erlacher M, Proietti M, Camacho-Ordonez N, Voll RE, Grimbacher B, Warnatz K, Salzer U, Rizzi M. Blood. 2020 Apr 23;135(17):1452-1457.
Incidence of SCID in Germany from 2014 to 2015 an ESPED* Survey on Behalf of the API*** Erhebungseinheit für Seltene Pädiatrische Erkrankungen in Deutschland (German Paediatric Surveillance Unit) ** Arbeitsgemeinschaft Pädiatrische Immunologie. Shai S, Perez-Becker R, Andres O, Bakhtiar S, Bauman U, von Bernuth H, Classen CF, Dückers G, El-Helou SM, Gangfuß A, Ghosh S, Grimbacher B, Hauck F, Hoenig M, Husain RA, Kindle G, Kipfmueller F, Klemann C, Krüger R, Lainka E, Lehmberg K, Lohrmann F, Morbach H, Naumann-Bartsch N, Oommen PT, Schulz A, Seidemann K, Speckmann C, Sykora KW, von Kries R, Niehues T. J Clin Immunol. 2020 Jul;40(5):708-717. doi: 10.1007/s10875-020-00782-x. Epub 2020 May 26. PMID: 32458183.
Clinical Phenotypes and Immunological Characteristics of 18 Egyptian LRBA Deficiency Patients. Meshaal S, El Hawary R, Adel R, Abd Elaziz D, Erfan A, Lotfy S, Hafez M, Hassan M, Johnson M, Rojas-Restrepo J, Gamez-Diaz L, Grimbacher B, Shoman W, Abdelmeguid Y, Boutros J, Galal N, El-Guindy N, Elmarsafy A. J Clin Immunol. 2020 Jun 6.
A novel NFKBIA variant substituting serine 36 of IκBα causes immunodeficiency with warts, bronchiectasis and juvenile rheumatoid arthritis in the absence of ectodermal dysplasia. Sogkas G, Adriawan IR, Ringshausen FC, Baumann U, Schröder C, Klemann C, von Hardenberg S, Schmidt G, Bernd A, Jablonka A, Ernst D, Schmidt RE, Atschekzei F. Clin Immunol. 2020 Jan;210:108269. 3,969 „doi: 10.1016/j.clim.2019.108269
Enabling External Inquiries to an Existing Patient Registry by Using the Open Source Registry System for Rare Diseases: Demonstration of the System Using the European Society for Immunodeficiencies Registry.Scheible R, Kadioglu D, Ehl S, Blum M, Boeker M, Folz M, Grimbacher B, Göbel J, Klein C, Nieters A, Rusch S, Kindle G, Storf H. JMIR Med Inform. 2020 Oct 7;8(10):e17420. doi: 10.2196/17420. PMID: 33026355; PMCID: PMC7578818.
Cancer Tendency in a Patient with ZNF341 Deficiency
S. Cekic, J. M. Hartberger, S. Frey-Jakobs, H. Huriyet, M. B. Hortoglu, J. C. Neubauer, et al.
Journal of Clinical Immunology 2020 Vol. 40 Issue 3 Pages 534-538 DOI: 10.1007/s10875-020-00756-z
Structural Noninfectious Manifestations of the Central Nervous System in Common Variable Immunodeficiency Disorders A. van de Ven, I. Mader, D. Wolff, S. Goldacker, H. Fuhrer, S. Rauer, et al. The Journal of Allergy and Clinical Immunology. In Practice 2020 Vol. 8 Issue 3 Pages 1047-1062.e6 DOI: 10.1016/j.jaip.2019.11.039
Long-term outcome of LRBA deficiency in 76 patients after various treatment modalities as evaluated by the immune deficiency and dysregulation activity (IDDA) score. Tesch VK, Abolhassani H, Shadur B, Zobel J, Mareika Y, Sharapova S, Karakoc-Aydiner E, Rivière JG, Garcia-Prat M, Moes N, Haerynck F, Gonzales-Granado LI, Santos Pérez JL, Mukhina A, Shcherbina A, Aghamohammadi A, Hammarström L, Dogu F, Haskologlu S, İkincioğulları AI, Bal SK, Baris S, Kilic SS, Karaca NE, Kutukculer N, Girschick H, Kolios A, Keles S, Uygun V, Stepensky P, Worth A, van Montfrans JM, Peters AM4, Meyts I, Adeli M, Marzollo A, Padem N, Khojah AM, Chavoshzadeh Z, Stefanija MA, Bakhtiar S, Florkin B, Meeths M, Gamez L, Grimbacher B, Seppänen MR, Lankester A, Gennery AR, Seidel MG; Inborn Errors, Clinical, and Registry Working Parties of the European Society for Blood and Marrow Transplantation (EBMT) and the European Society of Immunodeficiencies (ESID). J Allergy Clin Immunol. 2020 Dec 27. pii: S0091-6749(19)32603-X.
Distinct molecular response patterns of activating STAT3 mutations associate with penetrance of lymphoproliferation and autoimmunity. Jägle S, Heeg M, Grün S, Rensing-Ehl A, Maccari ME, Klemann C, Jones N, Lehmberg K, Bettoni C, Warnatz K, Grimbacher B, Biebl A, Schauer U, Hague R, Neth O, Mauracher A, Pachlopnik Schmid J, Fabre A, Kostyuchenko L, Führer M, Lorenz MR, Schwarz K, Rohr J, Ehl S. Clin Immunol. 2020 Nov 23;210:108316.
Publikationen 2019
The European Society for Immunodeficiencies (ESID) Registry Working Definitions for the Clinical Diagnosis of Inborn Errors of Immunity. Seidel MG, Kindle G, Gathmann B, Quinti I, Buckland M, van Montfrans J, Scheible R, Rusch S, Gasteiger LM, Grimbacher B, Mahlaoui N, Ehl S; ESID Registry Working Party and collaborators. J Allergy Clin Immunol Pract. 2019 Jul – Aug;7(6):1763-1770. Epub 2019 Feb 15.
Progressive Immunodeficiency with Gradual Depletion of B and CD4⁺ T Cells in Immunodeficiency, Centromeric Instability and Facial Anomalies Syndrome 2 (ICF2). Sogkas G, Dubrowinskaja N, Bergmann AK, Lentes J, Ripperger T, Fedchenko M, Ernst D, Jablonka A, Geffers R, Baumann U, Schmidt RE, Atschekzei F. Diseases. 2019 Apr 4;7(2):34.
Assessing the Functional Relevance of Variants in the IKAROS Family Zinc Finger Protein 1 (IKZF1) in a Cohort of Patients With Primary Immunodeficiency. Eskandarian Z, Fliegauf M, Bulashevska A, Proietti M, Hague R, Smulski CR, Schubert D, Warnatz K, Grimbacher B. Front Immunol. 2019 Apr 16;10:568. eCollection 2019. Erratum in: Front Immunol. 2019 Jun 28;10:1490.
Evaluating laboratory criteria for combined immunodeficiency in adult patients diagnosed with common variable immunodeficiency. von Spee-Mayer C, Koemm V, Wehr C, Goldacker S, Kindle G, Bulashevska A, Proietti M, Grimbacher B, Ehl S, Warnatz K. Clin Immunol. 2019 Jun;203:59-62. Epub 2019 Apr 17.
The German National Registry of Primary Immunodeficiencies (2012-2017). El-Helou SM, Biegner AK, Bode S, Ehl SR, Heeg M, Maccari ME, Ritterbusch H, Speckmann C, Rusch S, Scheible R, Warnatz K, Atschekzei F, Beider R, Ernst D, Gerschmann S, Jablonka A, Mielke G, Schmidt RE, Schürmann G, Sogkas G, Baumann UH, Klemann C, Viemann D, von Bernuth H, Krüger R, Hanitsch LG, Scheibenbogen CM, Wittke K, Albert MH, Eichinger A, Hauck F, Klein C, Rack-Hoch A, Sollinger FM, Avila A, Borte M, Borte S, Fasshauer M, Hauenherm A, Kellner N, Müller AH, Ülzen A, Bader P, Bakhtiar S, Lee JY, Heß U, Schubert R, Wölke S, Zielen S, Ghosh S, Laws HJ, Neubert J, Oommen PT, Hönig M, Schulz A, Steinmann S, Schwarz K, Dückers G, Lamers B, Langemeyer V, Niehues T, Shai S, Graf D, Müglich C, Schmalzing MT, Schwaneck EC, Tony HP, Dirks J, Haase G, Liese JG, Morbach H, Foell D, Hellige A, Wittkowski H, Masjosthusmann K, Mohr M, Geberzahn L, Hedrich CM, Müller C, Rösen-Wolff A, Roesler J, Zimmermann A, Behrends U, Rieber N, Schauer U, Handgretinger R, Holzer U, Henes J, Kanz L, Boesecke C, Rockstroh JK, Schwarze-Zander C, Wasmuth JC, Dilloo D, Hülsmann B, Schönberger S, Schreiber S, Zeuner R, Ankermann T, von Bismarck P, Huppertz HI, Kaiser-Labusch P, Greil J, Jakoby D, Kulozik AE, Metzler M, Naumann-Bartsch N, Sobik B, Graf N, Heine S, Kobbe R, Lehmberg K, Müller I, Herrmann F, Horneff G, Klein A, Peitz J, Schmidt N, Bielack S, Groß-Wieltsch U, Classen CF, Klasen J, Deutz P, Kamitz D, Lassay L, Tenbrock K, Wagner N, Bernbeck B, Brummel B, Lara-Villacanas E, Münstermann E, Schneider DT, Tietsch N, Westkemper M, Weiß M, Kramm C, Kühnle I, Kullmann S, Girschick H, Specker C, Vinnemeier-Laubenthal E, Haenicke H, Schulz C, Schweigerer L, Müller TG, Stiefel M, Belohradsky BH, Soetedjo V, Kindle G, Grimbacher B. Front Immunol. 2019 Jul 19;10:1272. eCollection 2019.
Late-Onset Antibody Deficiency Due to Monoallelic Alterations in NFKB1. Schröder C, Sogkas G, Fliegauf M, Dörk T, Liu D, Hanitsch LG, Steiner S, Scheibenbogen C, Jacobs R, Grimbacher B, Schmidt RE, Atschekzei F. Front Immunol. 2019 Nov 14;10:2618. eCollection 2019.
The architecture of the IgG anti-carbohydrate repertoire in primary antibody deficiencies. Jandus P, Boligan KF, Smith DF, de Graauw E, Grimbacher B, Jandus C, Abdelhafez MM, Despont A, Bovin N, Simon D, Rieben R, Simon HU, Cummings RD, von Gunten S. Blood. 2019 Nov 28;134(22):1941-1950.
Clinical and Immunological Phenotype of Patients With Primary Immunodeficiency Due to Damaging Mutations in NFKB2. Klemann C, Camacho-Ordonez N, Yang L, Eskandarian Z, Rojas-Restrepo JL, Frede N, Bulashevska A, Heeg M, Al-Ddafari MS, Premm J, Seidl M, Ammann S, Sherkat R, Radhakrishnan N, Warnatz K, Unger S, Kobbe R, Hüfner A, Leahy TR, Ip W, Burns SO, Fliegauf M, Grimbacher B. Front Immunol. 2019 Mar 19;10:297. doi: 10.3389/fimmu.2019.00297. PMID: 30941118; PMCID: PMC6435015.